Continuamos avanzando en el sistema IA de Dataprius.
El desarrollo y puesta en marcha de la «Base de conocimiento» sigue el calendario previsto.
En estos momentos ya disponemos de una versión «Beta».
Ya está disponible para ser enviada a todas aquellas empresas y usuarios que han solicitado participar en el plan de «Adopción Temprana».
El ritmo de desarrollo y de implantación de infraestructuras ha resultado extenuante para el equipo de desarrollo de Dataprius. Se ha empleado programación y técnicas propias del mundo de los videojuegos, todo con el fin de acelerar las comunicaciones y los procesos involucrados.

Momento actual del desarrollo de la IA
Como hemos dicho, entramos en fase de pruebas y puesta en marcha. Al mismo tiempo, el personal de Dataprius irá realizando los ajustes necesarios.
Hay que considerar que nuestro sistema ha de satisfacer las necesidades de un amplio espectro de sectores empresariales.
En primer lugar, estamos ajustando en funcionamiento según la temática de los archivos, es decir, la IA ha de obtener conocimiento de la temática propia de los archivos. Hablamos de los documentos que las empresas podrán incluir en la base de conocimiento. Estos archivos pueden corresponder a una amplia gama de áreas de conocimiento o de información almacenada específica.
Inicialmente estamos afinando para diferentes temáticas y sectores con diferentes tipos de documentos:
- Manuales convencionales y técnicos. Para todo tipo de sectores.
- Proyectos. En sectores técnicos como ingeniería, arquitectura y proyectos multi sectoriales en general.
- Informes. Para todo tipo de sectores.
- Documentos del sector sanitario.
- Archivos de contratos y presupuestos. En todo tipo de sectores.
- Facturas y documentos fiscales. Documentos de gestorías y asesorías.
- Documentos especializados muy específicos de cualquier área de conocimiento.
Recordamos el Concepto. Base de conocimiento IA de Dataprius
El objetivo es disponer de una IA privada. A modo de Chat-GPT o Copilot, esta IA responderá a cualquier pregunta. Esto se realiza, tomando como base la información de los documentos almacenados en Dataprius, los archivos que se han seleccionado a este propósito.
El sistema funciona en verdaderas condiciones de privacidad. Los archivos nunca salen del sistema Dataprius. El sistema considera las carpetas y sus permisos.
Técnicamente, a este tipo de soluciones se las denomina sistemas RAG («Retrieval Augmented Generation» )(Generación Aumentada por Recuperación).
Esquema de funcionamiento
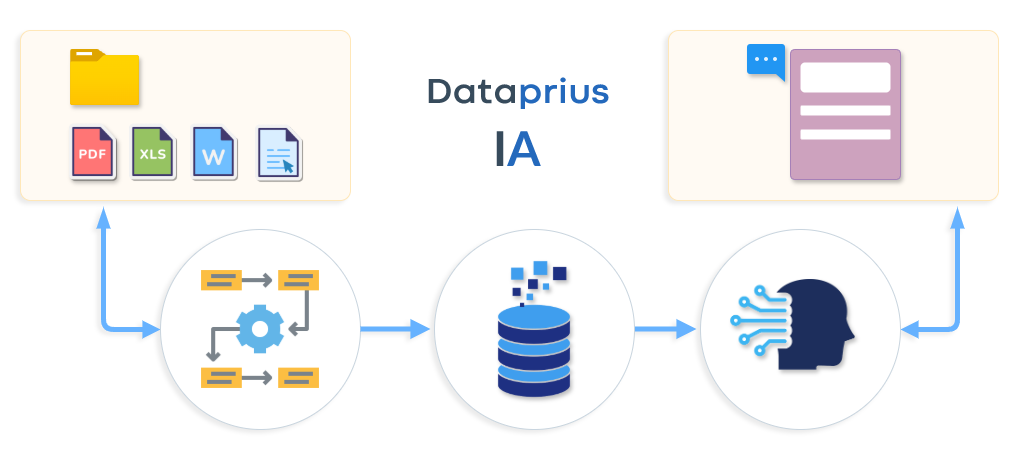
- Se selecciona una carpeta de las que tenemos almacenadas en el sistema.
- El sistema usa, aquellos archivos dentro de la carpeta, que se consideran Indexables. En estos momentos los archivos Indexables son aquellos con extensiones: [‘.pdf’, ‘.doc’, ‘.docx’, ‘.eml’, ‘.srt’, ‘.xls’, ‘.xlsx’, ‘.txt’, ‘.odt’, ‘.htm’, ‘.html’, ‘.rtf’]
- Tras la selección y la detección de los archivos Indexables, el sistema realiza el proceso de indexación.
- Este proceso consiste en extraer el texto de los archivos, partir en bloques los archivos y guardarlos en un formato especial que la IA entiende muy bien.
- Este proceso se realiza dentro del sistema Dataprius. Se garantiza la privacidad porque los archivos nunca salen del sistema. Al contrario que las IA’s públicas.
- Finalizado el proceso de Indexación ya podremos consultar a la IA.
Funcionamiento con capturas de pantalla.
Acceso desde el escritorio
Sobre el escritorio Dataprius, en la columna izquierda aparece el botón para acceder.
Este botón aparece solo para los usuarios registrados en el plan de Adopción Temprana.
Si es usuario de Dataprius y está interesado en probar, puede informarse en visitando el artículo: IA Base de conocimiento Dataprius.
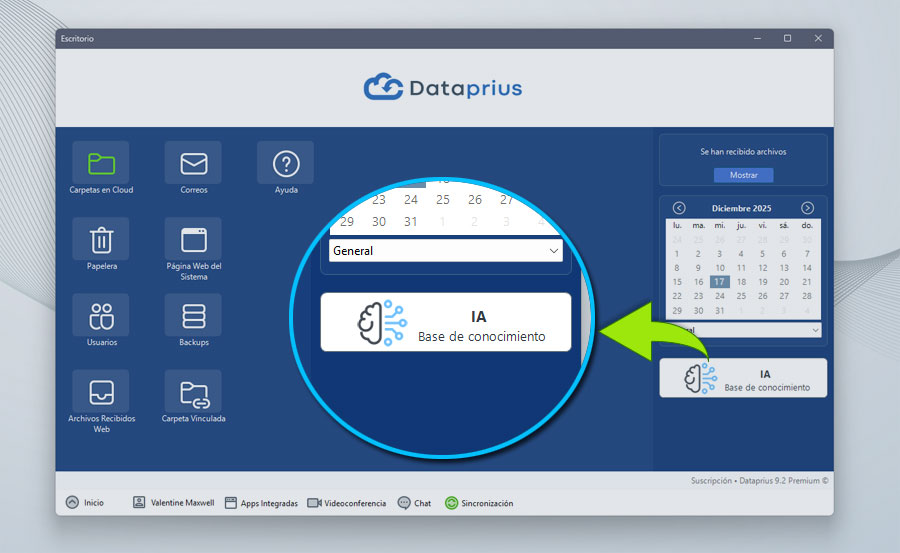
Ventana IA y configuración
La primera vez que accedemos el sistema nos indica que no hay archivos en la base de conocimiento.
Es necesario configurar.
La IA ha de disponer de archivos para su funcionamiento. Los archivos Indexados son aquellos que ya forman parte de la base de conocimiento.
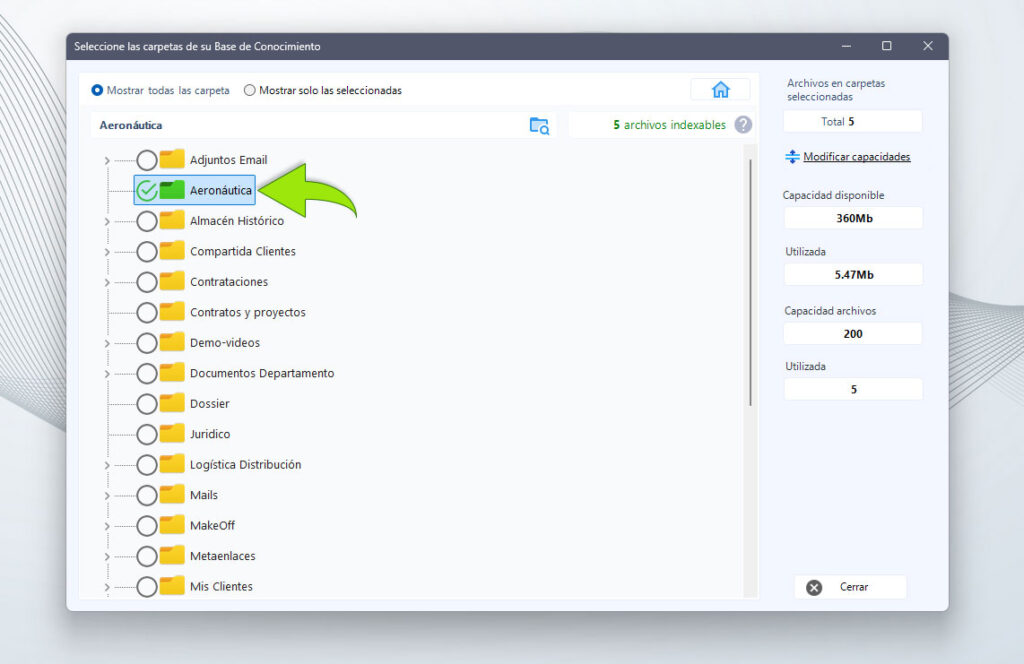
Configurando. Seleccionando carpetas.
Configurar consiste en seleccionar las carpetas que formarán parte de nuestra base de conocimiento.
Esas carpetas contienen los archivos que alimentan la IA.
Lo normal será montar carpetas específicas que contienen los documentos sobre los que queremos consultar.
Sobre la ventana, también puede verse que al hacer click sobre una carpeta se indica el número de archivos indexables. Es el recuento de los tipos de ficheros presentes en la carpeta y que pueden ser incorporados a la base de conocimiento:
[‘.pdf’, ‘.doc’, ‘.docx’, ‘.eml’, ‘.srt’, ‘.xls’, ‘.xlsx’, ‘.txt’, ‘.odt’, ‘.htm’, ‘.html’, ‘.rtf’]
Carpeta seleccionada. Iniciar Proceso de indexación.
Una vez seleccionada la carpeta que nos interesa. Podemos volver a la ventana principal. Cuando realizamos cambios en las carpetas y contenidos la ventana nos indicará si es necesario comenzar el proceso de Indexación.
Podemos: continuar configurando, cambiando las carpetas seleccionadas, agregando o quitando archivos o iniciar el proceso de Indexación.
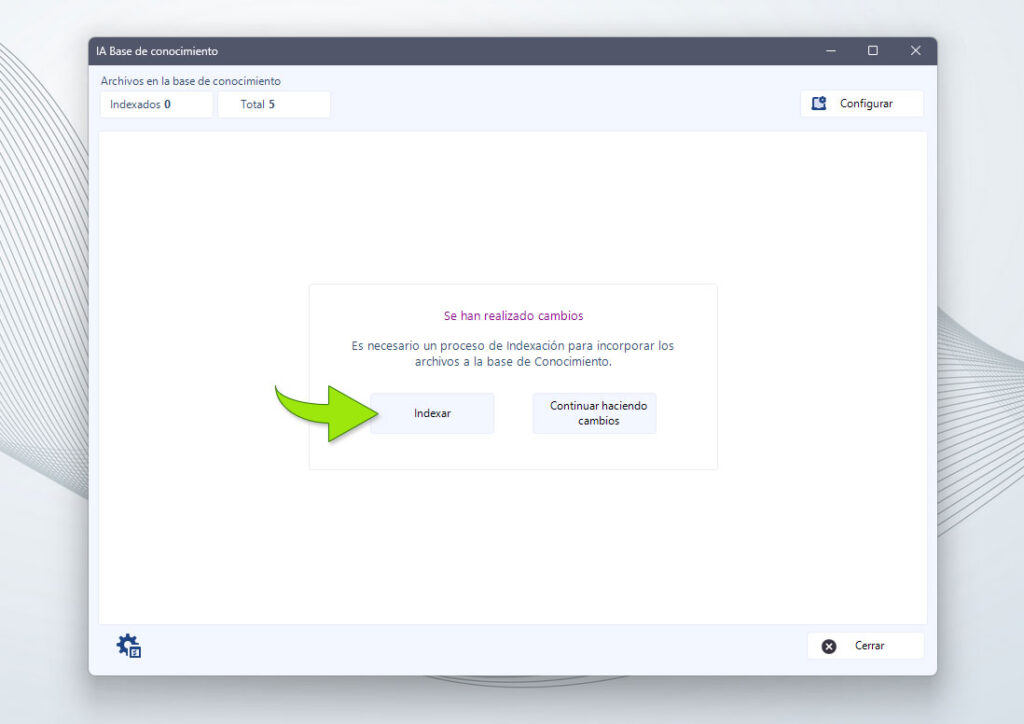
Proceso de indexación.
La duración del proceso de indexación depende de la cantidad de archivos, de sus tamaños y de sus tipos.
Podemos cerrar la ventana y el proceso continua. Es un proceso interno del sistema.
Mientras se realiza la indexación podemos consultar a la IA. Lo que ocurre es que responderá parcialmente porque aún no tiene todos los archivos que hemos indicado.
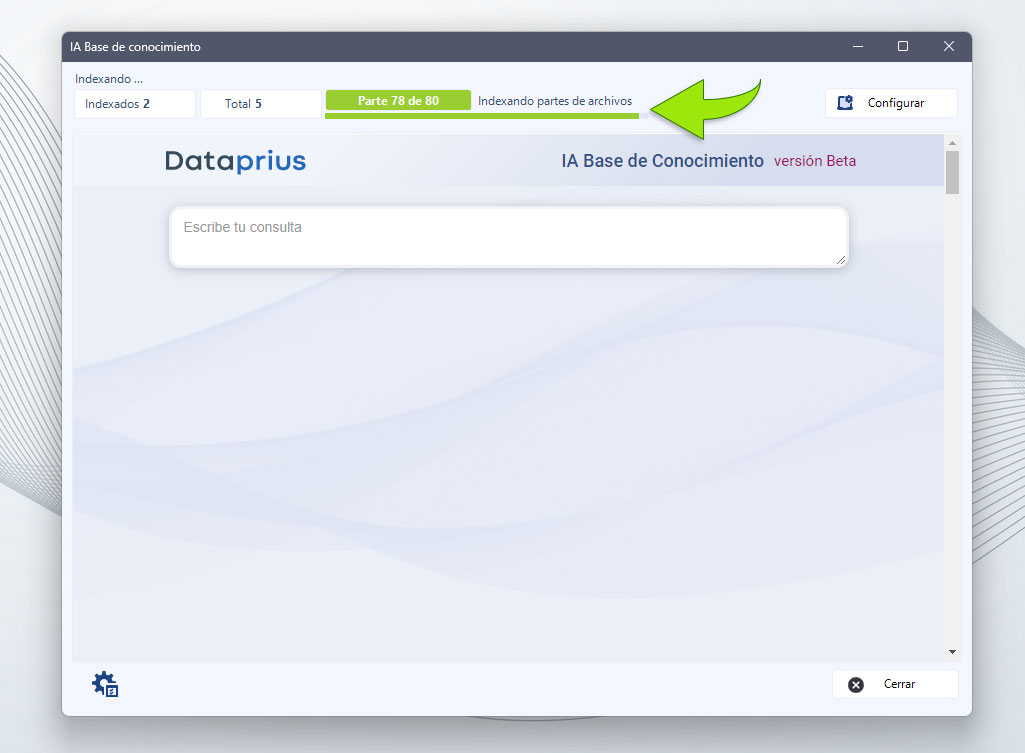
Consultando a la IA.
Cuando los archivos están indexados, la IA responderá a cualquier pregunta teniendo en cuenta nuestros documentos.
Las respuestas de la IA vendrán acompañadas de referencias a los ficheros y de imágenes extraídas de los mismos.
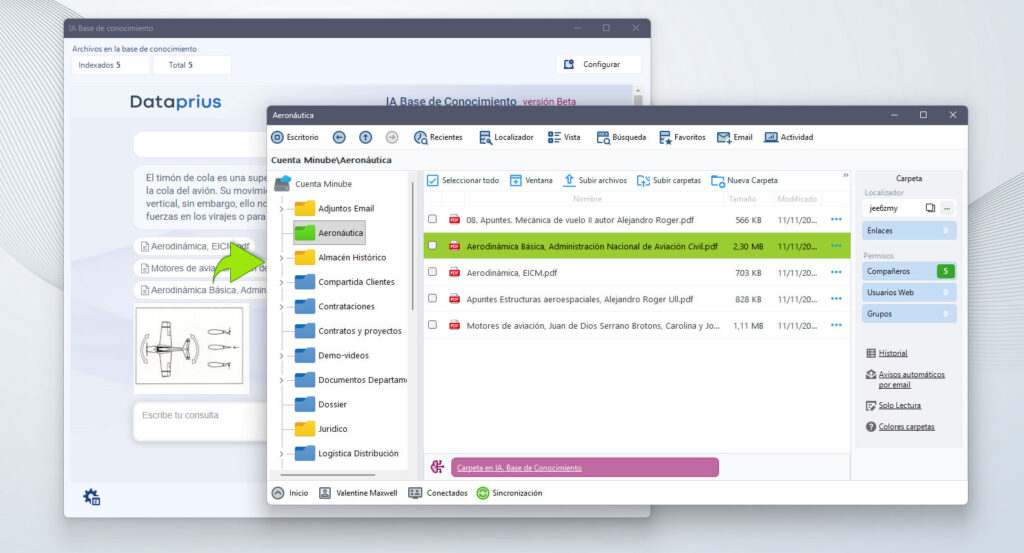
En este ejemplo hemos seleccionado una carpeta que contiene 5 libros de aeronáutica en formato PDF. Es una prueba sobre una temática específica. Vemos un ejemplo de cómo responde la IA a nuestras preguntas.
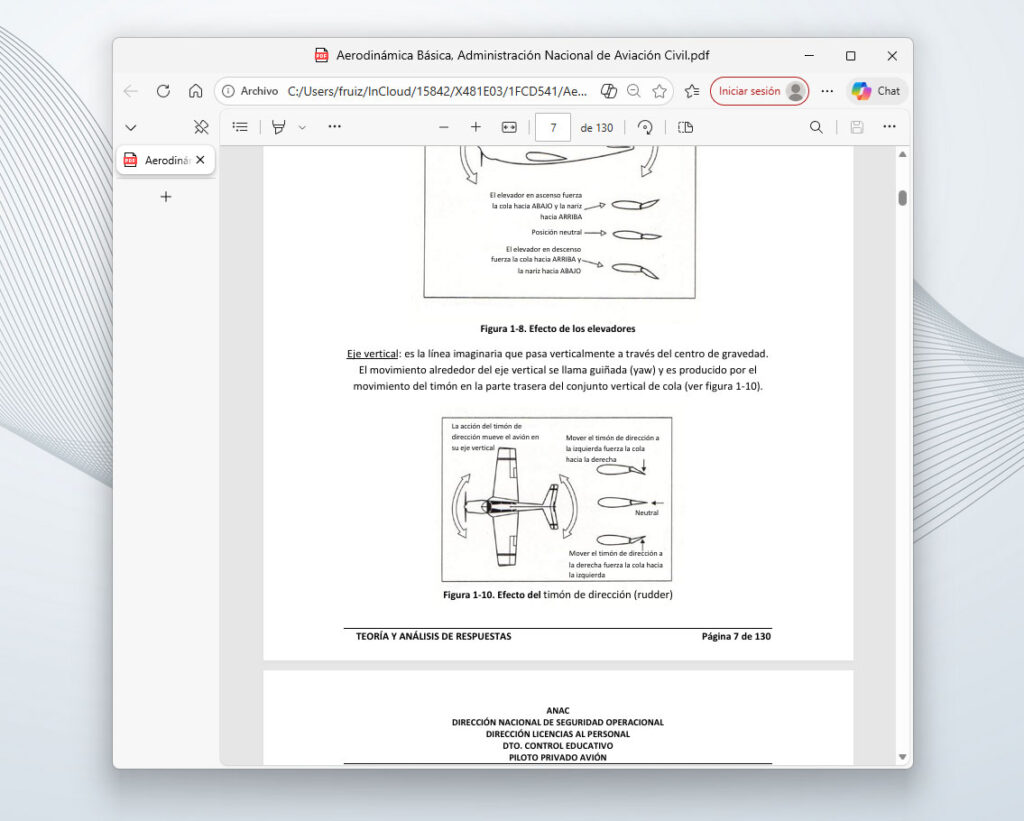
Realizamos una pregunta, evidentemente para que responda en base a nuestros documentos. Sobre aeronáutica en este caso: ¿Qué es el timón de cola?
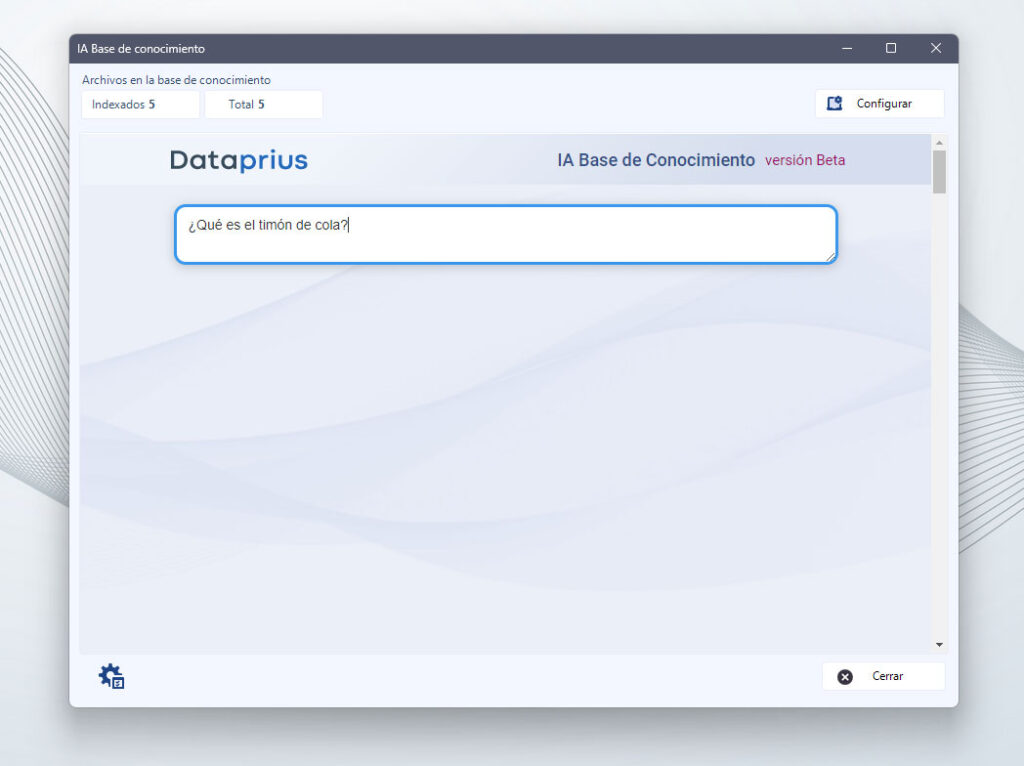
La respuesta.
¡Wow! Nuestra IA se ha convertido en experta en aeronáutica a partir de los archivos de nuestras carpetas.
Este es el objetivo. Las empresas y en general los usuarios de Dataprius pueden hacer la IA experta con sus propios documentos.
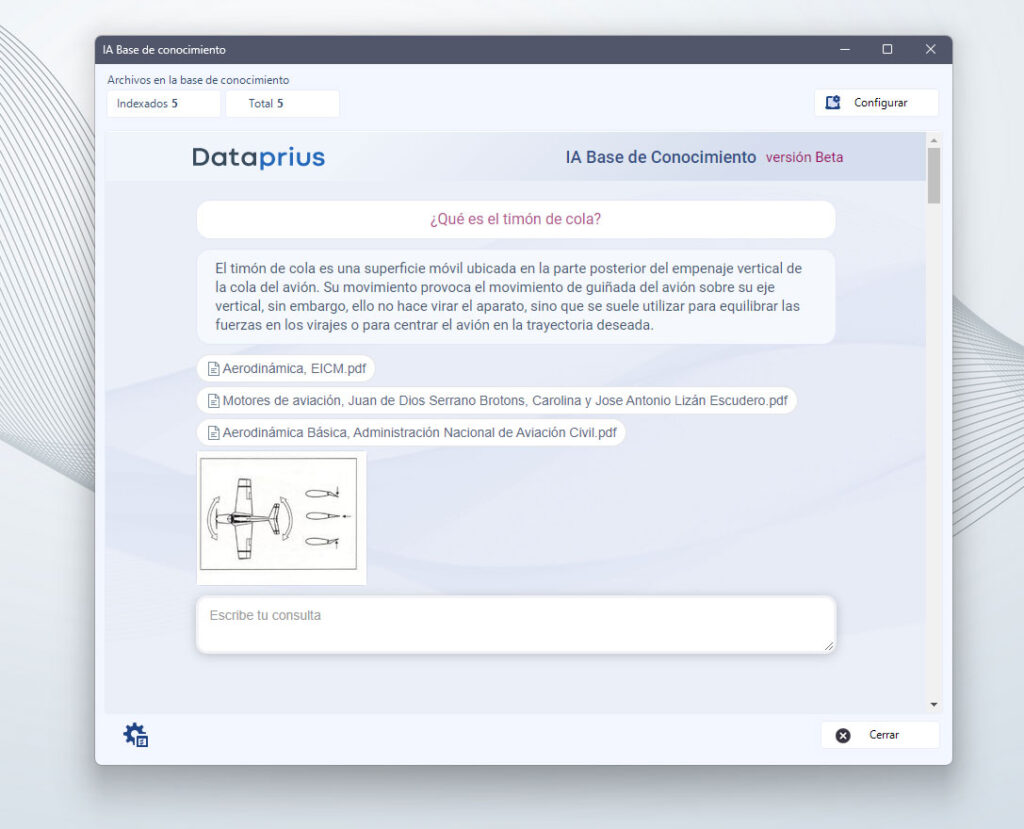
Detalle de las respuestas
Tal y como vemos en el ejemplo, la IA no solo ha respondido a nuestra pregunta, también nos muestra los archivos relacionados con la respuesta e imágenes.
Al hacer click sobre un archivo, el sistema abre la carpeta y nos lleva a su ubicación.
Conclusiones
El estado en la fase de desarrollo actual ya permite hacer un uso completo de la base de conocimiento.
Ahora, nuestra intención es realizar las mejoras y los afinamientos en el campo de batalla real, es decir, con los archivos de nuestros usuarios.
Nos estamos poniendo en contacto con todos los que han solicitado participar en el proyecto adhiriéndose como usuarios de Adopción Temprana. La experiencia que nos aporten servirá para perfeccionar el sistema y dotarlo de aquellas características que nuestros usuarios vean necesarias.
Próximos pasos
En cuanto hayamos realizado esta primera fase de pruebas pondremos la herramienta a disposición de todos nuestros usuarios. En breve enviaremos una comunicación tanto sobre la IA como las mejoras realizadas en el sistema. Publicaremos en este blog sobre casos de uso, ejemplos y evolución del sistema.
Como siempre, estamos disponibles para cualquier comentario, duda o sugerencia.
Que maravilla!! Va a agilizar los procesos de busqueda y la confeccion de informes….